
Data Annotation and Labelling: Automation vs. Manual Approaches
Data annotation and labeling are integral processes in the development of machine learning and artificial intelligence (AI) systems. These processes involve assigning meaningful labels to data, thereby enabling machines to learn from and make sense of complex datasets. In essence, data annotation and labeling transform raw data into a structured format that AI models can interpret and analyze, which is crucial for the accuracy and efficiency of these models.
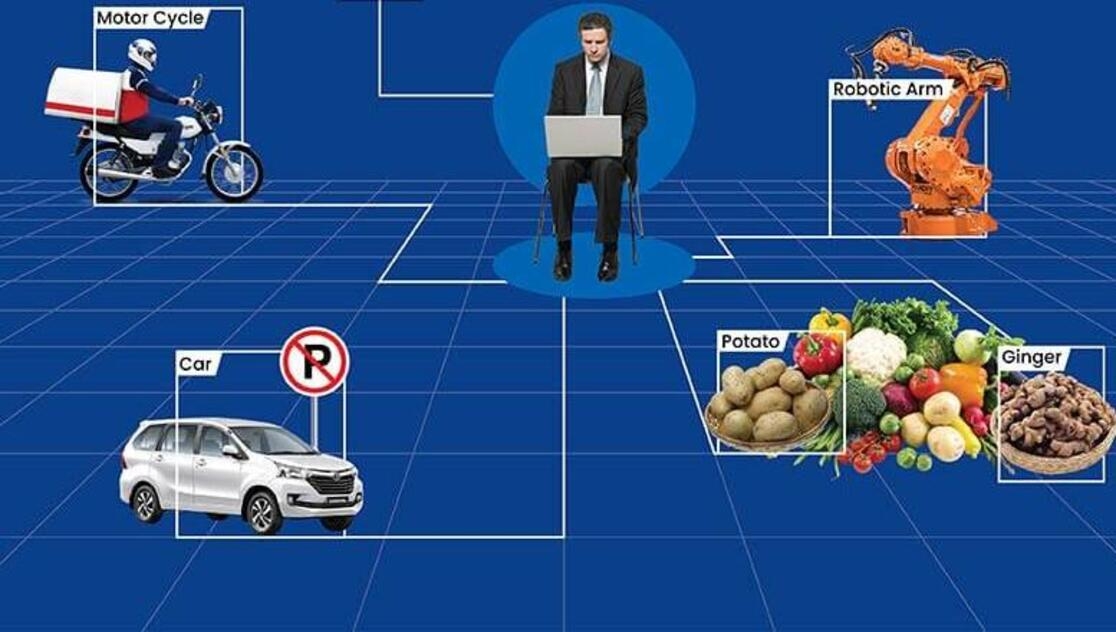
At its core, data annotation is the process of tagging or labeling data with relevant information. This can involve various forms of data, including text, images, audio, and video. For example, in natural language processing (NLP), text data may be annotated with parts of speech, named entities, or sentiment labels. In computer vision, images may be annotatedwith bounding boxes, keypoints, or segmentation masks to identify objects or features within the images. These annotations provide the contextual information that AI models need to understand and process the data accurately.
Labeling is a subset of data annotation that specifically involves assigning labels to data points. These labels act as ground truth references for training machine learning models. In supervised learning, labeled data is essential because it allows the model to learn the relationship between input data and the corresponding output labels. For instance, in a dataset of medical images, labels might indicate whether an image contains signs of a particular disease. The AI model can then be trained to recognize these signs in new, unlabeled images.
The accuracy of data annotation and labeling directly impacts the performance of AI models. Poorly annotated data can lead to incorrect predictions and unreliable results, which is why precision and consistency are paramount in these processes. Human annotators play a crucial role in ensuring high-quality annotations, though their work can be time-consuming and prone to error. To address this, automated annotation tools and techniques, such as machine learning-assisted annotation and active learning, have been developed to enhance efficiency and accuracy.
Despite advancements, data annotation and labeling still present several challenges. One significant challenge is the sheer volume of data that needs to be annotated. As datasets continue to grow in size and complexity, the demand for efficient and scalable annotation solutions increases. Additionally, achieving consistent and accurate annotations across different annotators and datasets can be difficult, necessitating robust quality control measures and standardized guidelines.
Data privacy and ethical considerations also come into play, particularly when dealing with sensitive data such as medical records or personal information. Ensuring that data annotation practices comply with privacy regulations and ethical standards is critical to maintaining trust and integrity in AI systems.
Looking ahead, the future of data annotation and labeling lies in the integration of advanced technologies such as artificial intelligence and automation. AI-driven annotation tools can significantly reduce the time and effort required for manual annotation, while improving accuracy and consistency. Furthermore, the development of new techniques for semi-supervised and unsupervised learning may reduce the reliance on large amounts of labeled data, making AI systems more efficient and scalable.
In summary, data annotation and labeling are foundational components of machine learning and AI development. They provide the necessary structure and context for AI models to learn from and interpret data. As the field continues to evolve, innovations in annotation techniques and tools will play a crucial role in advancing the capabilities and applications of AI systems.
https://www.marketdigits.com/data-annotation-and-labelling-market-1691737848
Data annotation and labeling are integral processes in the development of machine learning and artificial intelligence (AI) systems. These processes involve assigning meaningful labels to data, thereby enabling machines to learn from and make sense of complex datasets. In essence, data annotation and labeling transform raw data into a structured format that AI models can interpret and analyze, which is crucial for the accuracy and efficiency of these models.
At its core, data annotation is the process of tagging or labeling data with relevant information. This can involve various forms of data, including text, images, audio, and video. For example, in natural language processing (NLP), text data may be annotated with parts of speech, named entities, or sentiment labels. In computer vision, images may be annotatedwith bounding boxes, keypoints, or segmentation masks to identify objects or features within the images. These annotations provide the contextual information that AI models need to understand and process the data accurately.
Labeling is a subset of data annotation that specifically involves assigning labels to data points. These labels act as ground truth references for training machine learning models. In supervised learning, labeled data is essential because it allows the model to learn the relationship between input data and the corresponding output labels. For instance, in a dataset of medical images, labels might indicate whether an image contains signs of a particular disease. The AI model can then be trained to recognize these signs in new, unlabeled images.
The accuracy of data annotation and labeling directly impacts the performance of AI models. Poorly annotated data can lead to incorrect predictions and unreliable results, which is why precision and consistency are paramount in these processes. Human annotators play a crucial role in ensuring high-quality annotations, though their work can be time-consuming and prone to error. To address this, automated annotation tools and techniques, such as machine learning-assisted annotation and active learning, have been developed to enhance efficiency and accuracy.
Despite advancements, data annotation and labeling still present several challenges. One significant challenge is the sheer volume of data that needs to be annotated. As datasets continue to grow in size and complexity, the demand for efficient and scalable annotation solutions increases. Additionally, achieving consistent and accurate annotations across different annotators and datasets can be difficult, necessitating robust quality control measures and standardized guidelines.
Data privacy and ethical considerations also come into play, particularly when dealing with sensitive data such as medical records or personal information. Ensuring that data annotation practices comply with privacy regulations and ethical standards is critical to maintaining trust and integrity in AI systems.
Looking ahead, the future of data annotation and labeling lies in the integration of advanced technologies such as artificial intelligence and automation. AI-driven annotation tools can significantly reduce the time and effort required for manual annotation, while improving accuracy and consistency. Furthermore, the development of new techniques for semi-supervised and unsupervised learning may reduce the reliance on large amounts of labeled data, making AI systems more efficient and scalable.
In summary, data annotation and labeling are foundational components of machine learning and AI development. They provide the necessary structure and context for AI models to learn from and interpret data. As the field continues to evolve, innovations in annotation techniques and tools will play a crucial role in advancing the capabilities and applications of AI systems.
https://www.marketdigits.com/data-annotation-and-labelling-market-1691737848
Data Annotation and Labelling: Automation vs. Manual Approaches
Data annotation and labeling are integral processes in the development of machine learning and artificial intelligence (AI) systems. These processes involve assigning meaningful labels to data, thereby enabling machines to learn from and make sense of complex datasets. In essence, data annotation and labeling transform raw data into a structured format that AI models can interpret and analyze, which is crucial for the accuracy and efficiency of these models.
At its core, data annotation is the process of tagging or labeling data with relevant information. This can involve various forms of data, including text, images, audio, and video. For example, in natural language processing (NLP), text data may be annotated with parts of speech, named entities, or sentiment labels. In computer vision, images may be annotatedwith bounding boxes, keypoints, or segmentation masks to identify objects or features within the images. These annotations provide the contextual information that AI models need to understand and process the data accurately.
Labeling is a subset of data annotation that specifically involves assigning labels to data points. These labels act as ground truth references for training machine learning models. In supervised learning, labeled data is essential because it allows the model to learn the relationship between input data and the corresponding output labels. For instance, in a dataset of medical images, labels might indicate whether an image contains signs of a particular disease. The AI model can then be trained to recognize these signs in new, unlabeled images.
The accuracy of data annotation and labeling directly impacts the performance of AI models. Poorly annotated data can lead to incorrect predictions and unreliable results, which is why precision and consistency are paramount in these processes. Human annotators play a crucial role in ensuring high-quality annotations, though their work can be time-consuming and prone to error. To address this, automated annotation tools and techniques, such as machine learning-assisted annotation and active learning, have been developed to enhance efficiency and accuracy.
Despite advancements, data annotation and labeling still present several challenges. One significant challenge is the sheer volume of data that needs to be annotated. As datasets continue to grow in size and complexity, the demand for efficient and scalable annotation solutions increases. Additionally, achieving consistent and accurate annotations across different annotators and datasets can be difficult, necessitating robust quality control measures and standardized guidelines.
Data privacy and ethical considerations also come into play, particularly when dealing with sensitive data such as medical records or personal information. Ensuring that data annotation practices comply with privacy regulations and ethical standards is critical to maintaining trust and integrity in AI systems.
Looking ahead, the future of data annotation and labeling lies in the integration of advanced technologies such as artificial intelligence and automation. AI-driven annotation tools can significantly reduce the time and effort required for manual annotation, while improving accuracy and consistency. Furthermore, the development of new techniques for semi-supervised and unsupervised learning may reduce the reliance on large amounts of labeled data, making AI systems more efficient and scalable.
In summary, data annotation and labeling are foundational components of machine learning and AI development. They provide the necessary structure and context for AI models to learn from and interpret data. As the field continues to evolve, innovations in annotation techniques and tools will play a crucial role in advancing the capabilities and applications of AI systems.
https://www.marketdigits.com/data-annotation-and-labelling-market-1691737848
0 Comentários
0 Compartilhamentos